How to simulate antigen or disease-associated signals in AIRR datasets
In immuneML, it is possible to implant signals in a repertoire dataset in order to simulate the effect of an immune event on the repertoires. This is done using the Simulation instruction in the YAML specification. Any type of repertoire dataset (experimental or simulated) can be used as a starting point for an immune event simulation.
To import an existing dataset that will be used as a baseline for implanting immune signals, see How to import data into immuneML. Alternatively, to generate a dataset consisting of random sequences, see How to generate a random sequence, receptor or repertoire dataset.
YAML specification of the Simulation instruction for introducing immune signals
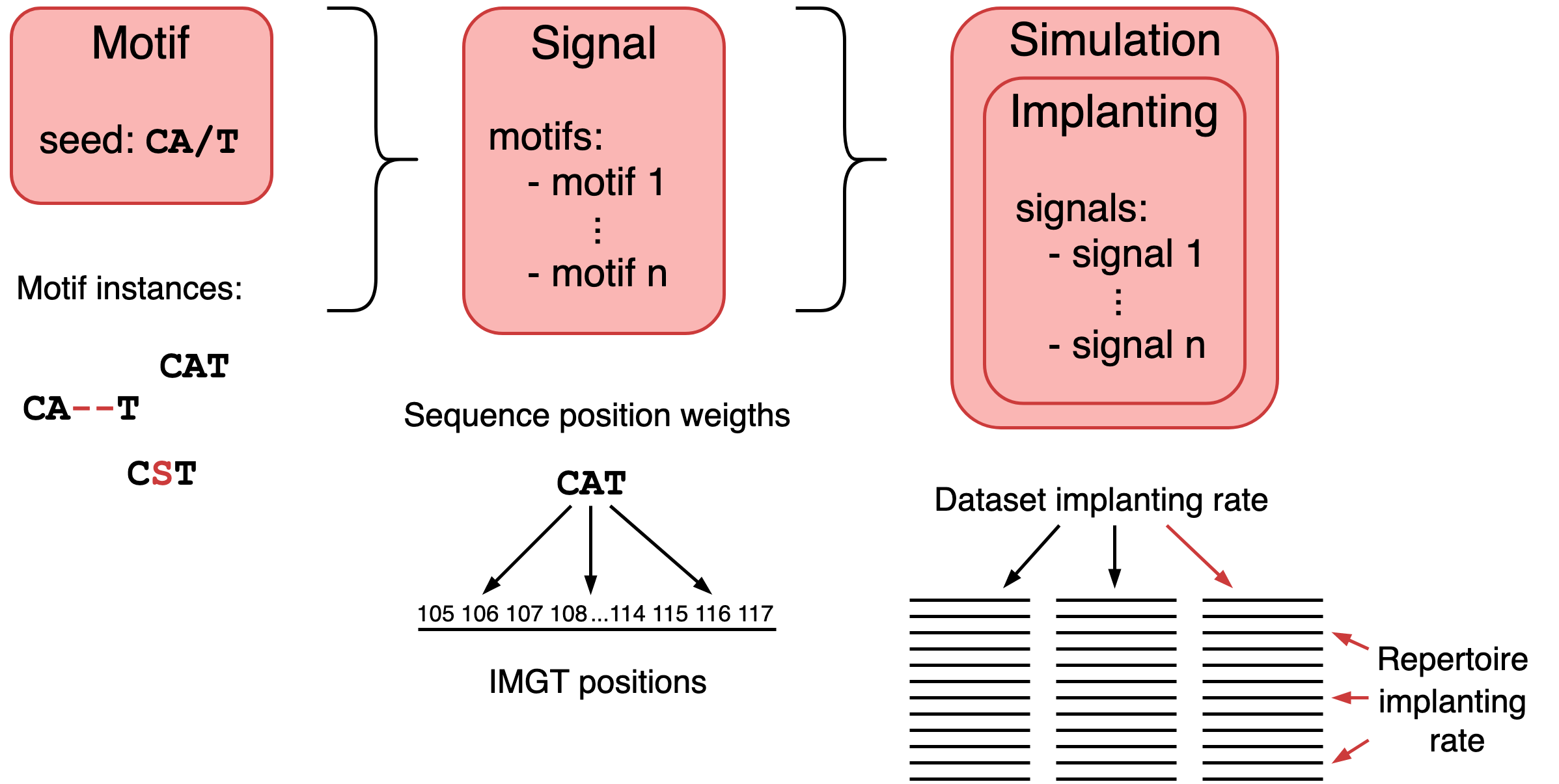
The YAML definition consists of three components: motif, signal and simulation definitions.
motifs(see: Motif) are defined by (i) the seed (sequence of amino acids), (ii) the way they are instantiated from the seed and (iii) a list of parameters for the instantiation. For gapped k-mer instantiation, the parameters are Hamming distance probabilities (probability for every distance value is explicitly given, the gap positions will not be taken into account), minimal and maximal gap size (if a gap is specified in the seed) and alphabet weights (probability for each amino acid to replace one of the amino acids in the seed when the Hamming distance between the seed and the motif instance is equal to or larger than 1). It is possible to define multiple motifs by defining a key before specifying the parameters of the motif.signals(see: Signal) model immune events and represent the labels assigned to the repertoires (the label is ‘signal_my_signal_name’ for signal calledmy_signal_namein the YAML specification, and can have value True or False in the repertoire depending whether the signal was implanted in the repertoire or not). A signal is defined by a list of motifs (only motif keys as given in the previous section are specified in the list), the sequence position weights (probabilities to implant a motif instance into a target receptor sequence at the given IMGT position) and implanting (the way receptor sequences are chosen for implanting from the repertoire). Implanting and the list of motifs are mandatory fields in the YAML specification.simulationsdefines how the signals will be combined and implanted in the repertoires. Within a simulation, one or more implantings can be specified. Each implanting only affects its own partition of the dataset, so each repertoire can only receive implanted signals from one implanting. This way, implantings can be used to ensure signals do not overlap (one implanting per signal), or to ensure signals always occur together (multiple signals per implanting).For each implanting, it is necessary to define:
A
dataset_implanting_rate: the percentage of repertoires in the dataset which will contain the listed signalsA
repertoire_implanting_rate: the percentage of receptor sequences in the repertoire which will contain the listed signalsA list of
signalsfor which this applies. When multiple signals are specified within one implanting, these signals are implanted in the same repertoires. However, they are not implanted within the same receptors in those repertoires. When specifying multiple different implantings, keep in mind that the summeddataset_implanting_ratecan not exceed 1.
This figure shows how the different concepts in a Simulation relate to each other:
See also the tutorial about recovering simulated immune signals.
An example of a simulation with disease-associated signals is given below. In this example, the healthy individuals are here represented by a randomly generated synthetic dataset (see: How to generate a random sequence, receptor or repertoire dataset). It is also possible to use experimental datasets as a baseline for the simulation (see Datasets for details how to import datasets from different formats).
definitions:
datasets:
my_synthetic_dataset: # A synthetic dataset is generated on the fly. Alternatively, data import from files may be specified.
format: RandomRepertoireDataset
params:
repertoire_count: 100
sequence_count_probabilities:
100: 0.5
120: 0.5
sequence_length_probabilities:
12: 0.33
14: 0.33
15: 0.33
labels: {}
motifs:
my_simple_motif: # a simple motif without gaps or hamming distance
seed: AAA
instantiation: GappedKmer
my_complex_motif: # complex motif containing a gap + hamming distance
seed: AA/A # ‘/’ denotes gap position if present, if not, there’s no gap
instantiation:
GappedKmer:
min_gap: 1
max_gap: 2
hamming_distance_probabilities: # probabilities for each number of
0: 0.7 # modification to the seed
1: 0.3
position_weights: # probabilities for modification per position
0: 1
1: 0 # note that index 2, the position of the gap,
3: 0 # is excluded from position_weights
alphabet_weights: # probabilities for using each amino acid in
A: 0.2 # a hamming distance modification
C: 0.2
D: 0.4
E: 0.2
signals:
my_signal:
motifs:
- my_simple_motif
- my_complex_motif
implanting: HealthySequence
sequence_position_weights:
109: 0.1
110: 0.2
111: 0.5
112: 0.1
simulations:
my_simulation:
my_implanting:
signals:
- my_signal
dataset_implanting_rate: 0.5
repertoire_implanting_rate: 0.25
instructions:
my_simulation_instruction:
type: Simulation
dataset: my_synthetic_dataset
simulation: my_simulation
export_formats: [AIRR, ImmuneML] # export the simulated dataset to these formats