immuneML.reports.ml_reports package¶
Submodules¶
immuneML.reports.ml_reports.BinaryFeaturePrecisionRecall module¶
- class immuneML.reports.ml_reports.BinaryFeaturePrecisionRecall.BinaryFeaturePrecisionRecall(train_dataset: Dataset = None, test_dataset: Dataset = None, method: BinaryFeatureClassifier = None, result_path: Path = None, name: str = None, hp_setting: HPSetting = None, label=None, number_of_processes: int = 1)[source]¶
Bases:
MLReportPlots the precision and recall scores for each added feature to the collection of features selected by the BinaryFeatureClassifier.
YAML specification:
definitions: reports: my_report: BinaryFeaturePrecisionRecall
- classmethod build_object(**kwargs)[source]¶
Creates the object of the subclass of the Report class from the parameters so that it can be used in the analysis. Depending on the type of the report, the parameters provided here will be provided in parsing time, while the other necessary parameters (e.g., subset of the data from which the report should be created) will be provided at runtime. For more details, see specific direct subclasses of this class, describing different types of reports.
- Parameters:
**kwargs – keyword arguments that will be provided by users in the specification (if immuneML is used as a command line tool) or in the dictionary when calling the method from the code, and which should be used to create the report object
- Returns:
the object of the appropriate report class
- check_prerequisites()[source]¶
Checks prerequisites for the generation of the report of specific class (e.g., if the class of the MLMethod instance is the one required by the report, if the data has been encoded to make a report of encoded dataset). In the instructions in immuneML, this function is used to determine whether to call generate_report() in the specific situation. Each report subclass has its own set of prerequisites. If the report cannot be run, the information on this will be logged and the report skipped in the specific situation. No error will be raised. See subclasses of the class
Instructionfor more information on how the reports are executed.- Returns:
boolean value True if the prerequisites are o.k., and False otherwise.
immuneML.reports.ml_reports.CoefficientPlottingSetting module¶
immuneML.reports.ml_reports.CoefficientPlottingSettingList module¶
immuneML.reports.ml_reports.Coefficients module¶
- class immuneML.reports.ml_reports.Coefficients.Coefficients(coefs_to_plot: CoefficientPlottingSettingList, cutoff: list, n_largest: list, train_dataset: Dataset = None, test_dataset: Dataset = None, method: MLMethod = None, result_path: Path = None, name: str = None, hp_setting: HPSetting = None, label=None, number_of_processes: int = 1)[source]¶
Bases:
MLReportA report that plots the coefficients for a given ML method in a barplot. Can be used for LogisticRegression, SVM, SVC, and RandomForestClassifier. In the case of RandomForest, the feature importances will be plotted.
When used in TrainMLModel instruction, the report can be specified under ‘models’, both on the selection and assessment levels.
Which coefficients should be plotted (for example: only nonzero, above a certain threshold, …) can be specified. Multiple options can be specified simultaneously. By default the 25 largest coefficients are plotted. The full set of coefficients will also be exported as a csv file.
Example output:
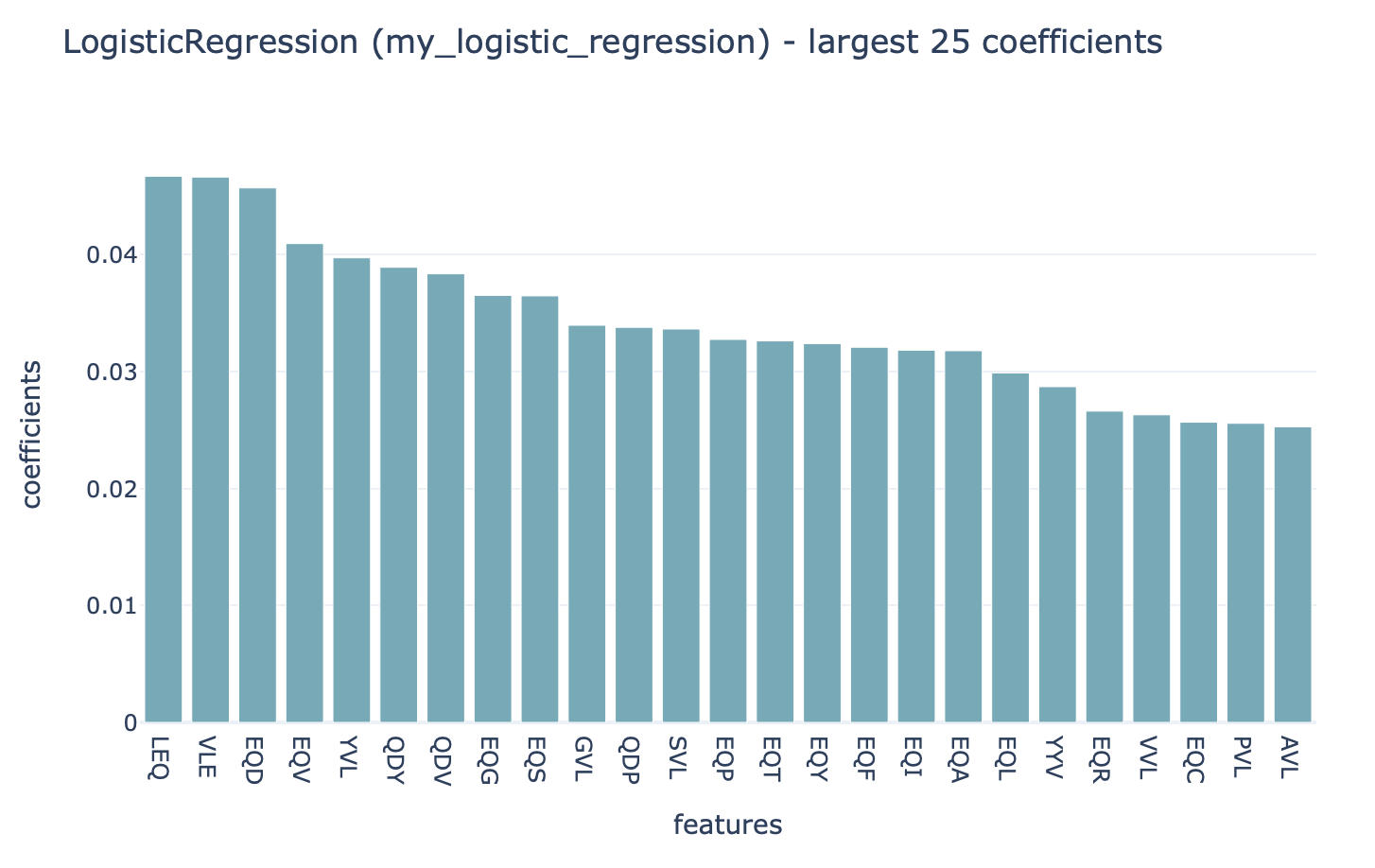
Specification arguments:
coefs_to_plot (list): A list specifying which coefficients should be plotted. For options see
CoefficientPlottingSetting.cutoff (list): If ‘cutoff’ is specified under ‘coefs_to_plot’, the cutoff values can be specified here. The coefficients which have an absolute value equal to or greater than the cutoff will be plotted.
n_largest (list): If ‘n_largest’ is specified under ‘coefs_to_plot’, the values for n can be specified here. These should be integer values. The n largest coefficients are determined based on their absolute values.
YAML specification:
definitions: reports: my_coef_report: Coefficients: coefs_to_plot: - all - nonzero - cutoff - n_largest cutoff: - 0.1 - 0.01 n_largest: - 5 - 10
- classmethod build_object(**kwargs)[source]¶
Creates the object of the subclass of the Report class from the parameters so that it can be used in the analysis. Depending on the type of the report, the parameters provided here will be provided in parsing time, while the other necessary parameters (e.g., subset of the data from which the report should be created) will be provided at runtime. For more details, see specific direct subclasses of this class, describing different types of reports.
- Parameters:
**kwargs – keyword arguments that will be provided by users in the specification (if immuneML is used as a command line tool) or in the dictionary when calling the method from the code, and which should be used to create the report object
- Returns:
the object of the appropriate report class
- check_prerequisites()[source]¶
Checks prerequisites for the generation of the report of specific class (e.g., if the class of the MLMethod instance is the one required by the report, if the data has been encoded to make a report of encoded dataset). In the instructions in immuneML, this function is used to determine whether to call generate_report() in the specific situation. Each report subclass has its own set of prerequisites. If the report cannot be run, the information on this will be logged and the report skipped in the specific situation. No error will be raised. See subclasses of the class
Instructionfor more information on how the reports are executed.- Returns:
boolean value True if the prerequisites are o.k., and False otherwise.
immuneML.reports.ml_reports.ConfounderAnalysis module¶
- class immuneML.reports.ml_reports.ConfounderAnalysis.ConfounderAnalysis(metadata_labels: List[str], train_dataset: Dataset = None, test_dataset: Dataset = None, method: MLMethod = None, result_path: Path = None, name: str = None, hp_setting: HPSetting = None, label=None, number_of_processes: int = 1)[source]¶
Bases:
MLReportA report that plots the numbers of false positives and false negatives with respect to each value of the metadata features specified by the user. This allows checking whether a given machine learning model makes more misclassifications for some values of a metadata feature than for the others.
Specification arguments:
metadata_labels (list): A list of the metadata features to use as a basis for the calculations
YAML specification:
definitions: reports: my_confounder_report: ConfounderAnalysis: metadata_labels: - age - sex
- classmethod build_object(**kwargs)[source]¶
Creates the object of the subclass of the Report class from the parameters so that it can be used in the analysis. Depending on the type of the report, the parameters provided here will be provided in parsing time, while the other necessary parameters (e.g., subset of the data from which the report should be created) will be provided at runtime. For more details, see specific direct subclasses of this class, describing different types of reports.
- Parameters:
**kwargs – keyword arguments that will be provided by users in the specification (if immuneML is used as a command line tool) or in the dictionary when calling the method from the code, and which should be used to create the report object
- Returns:
the object of the appropriate report class
immuneML.reports.ml_reports.ConfusionMatrix module¶
- class immuneML.reports.ml_reports.ConfusionMatrix.ConfusionMatrix(train_dataset: Dataset = None, test_dataset: Dataset = None, method: MLMethod = None, result_path: Path = None, name: str = None, hp_setting=None, label=None, number_of_processes: int = 1, alternative_label: str = None)[source]¶
Bases:
MLReportA report that plots the confusion matrix for a trained ML method. Supports both binary and multiclass classification.
Specification arguments:
alternative_label (str): optionally, the confusion matrix can be split between different values of an alternative label. This may be useful to compare performance across different data subsets (e.g., batches, sources). If specified, separate confusion matrices will be generated for each value of the alternative label. Default is None.
YAML specification:
definitions: reports: my_conf_mat_report: ConfusionMatrix
- classmethod build_object(**kwargs)[source]¶
Creates the object of the subclass of the Report class from the parameters so that it can be used in the analysis. Depending on the type of the report, the parameters provided here will be provided in parsing time, while the other necessary parameters (e.g., subset of the data from which the report should be created) will be provided at runtime. For more details, see specific direct subclasses of this class, describing different types of reports.
- Parameters:
**kwargs – keyword arguments that will be provided by users in the specification (if immuneML is used as a command line tool) or in the dictionary when calling the method from the code, and which should be used to create the report object
- Returns:
the object of the appropriate report class
- check_prerequisites()[source]¶
Checks prerequisites for the generation of the report of specific class (e.g., if the class of the MLMethod instance is the one required by the report, if the data has been encoded to make a report of encoded dataset). In the instructions in immuneML, this function is used to determine whether to call generate_report() in the specific situation. Each report subclass has its own set of prerequisites. If the report cannot be run, the information on this will be logged and the report skipped in the specific situation. No error will be raised. See subclasses of the class
Instructionfor more information on how the reports are executed.- Returns:
boolean value True if the prerequisites are o.k., and False otherwise.
immuneML.reports.ml_reports.DeepRCMotifDiscovery module¶
- class immuneML.reports.ml_reports.DeepRCMotifDiscovery.DeepRCMotifDiscovery(n_steps, threshold, train_dataset: Dataset = None, test_dataset: Dataset = None, method: MLMethod = None, result_path: Path = None, name: str = None, hp_setting: HPSetting = None, label=None, number_of_processes: int = 1)[source]¶
Bases:
MLReportThis report plots the contributions of (i) input sequences and (ii) kernels to trained DeepRC model with respect to the test dataset. Contributions are computed using integrated gradients (IG). This report produces two figures:
inputs_integrated_gradients: Shows the contributions of the characters within the input sequences (test dataset) that was most important for immune status prediction of the repertoire. IG is only applied to sequences of positive class repertoires.
kernel_integrated_gradients: Shows the 1D CNN kernels with the highest contribution over all positions and amino acids.
For both inputs and kernels: Larger characters in the extracted motifs indicate higher contribution, with blue indicating positive contribution and red indicating negative contribution towards the prediction of the immune status. For kernels only: contributions to positional encoding are indicated by < (beginning of sequence), ∧ (center of sequence), and > (end of sequence).
See DeepRCMotifDiscovery for repertoire classification for a more detailed example.
Reference:
Widrich, M., et al. (2020). Modern Hopfield Networks and Attention for Immune Repertoire Classification. Advances in Neural Information Processing Systems, 33. https://proceedings.neurips.cc//paper/2020/hash/da4902cb0bc38210839714ebdcf0efc3-Abstract.html
Example output:
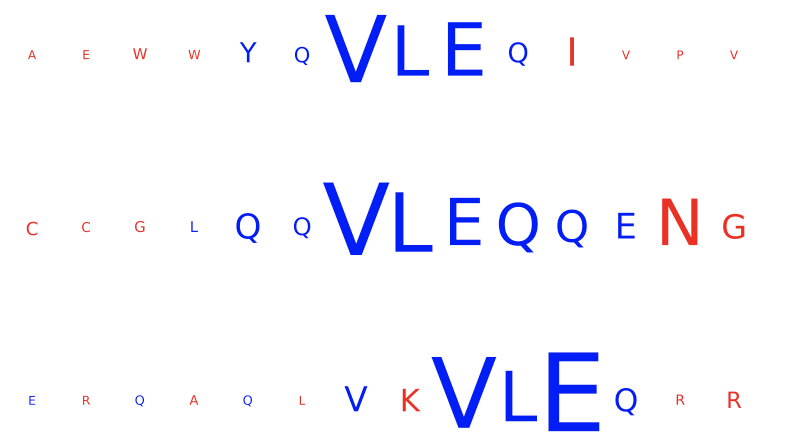

Specification arguments:
n_steps (int): Number of IG steps (more steps -> better path integral -> finer contribution values). 50 is usually good enough.
threshold (float): Only applies to the plotting of kernels. Contributions are normalized to range [0, 1], and only kernels with normalized contributions above threshold are plotted.
YAML specification:
definitions: reports: my_deeprc_report: DeepRCMotifDiscovery: threshold: 0.5 n_steps: 50
- classmethod build_object(**kwargs)[source]¶
Creates the object of the subclass of the Report class from the parameters so that it can be used in the analysis. Depending on the type of the report, the parameters provided here will be provided in parsing time, while the other necessary parameters (e.g., subset of the data from which the report should be created) will be provided at runtime. For more details, see specific direct subclasses of this class, describing different types of reports.
- Parameters:
**kwargs – keyword arguments that will be provided by users in the specification (if immuneML is used as a command line tool) or in the dictionary when calling the method from the code, and which should be used to create the report object
- Returns:
the object of the appropriate report class
- check_prerequisites()[source]¶
Checks prerequisites for the generation of the report of specific class (e.g., if the class of the MLMethod instance is the one required by the report, if the data has been encoded to make a report of encoded dataset). In the instructions in immuneML, this function is used to determine whether to call generate_report() in the specific situation. Each report subclass has its own set of prerequisites. If the report cannot be run, the information on this will be logged and the report skipped in the specific situation. No error will be raised. See subclasses of the class
Instructionfor more information on how the reports are executed.- Returns:
boolean value True if the prerequisites are o.k., and False otherwise.
- compute_contributions(intgrds_set_loader: DataLoader, deeprc_model, n_steps: int = 50, threshold: float = 0.5, path_inputs: Path = PosixPath('inputs_integrated_gradients.pdf'), path_kernels: Path = PosixPath('kernel_integrated_gradients.pdf'))[source]¶
Compute and plot contributions of sequences and motifs to trained DeepRC model, given a dataset. Contribution is computed using integrated gradients (IG).
Author – Michael Widrich Created on – 2020-07-20 Contact – michael.widrich@jku.at
Parameters¶
- intgrds_set_loadertorch.utils.data.DataLoader
The dataset to compute IG for in form of a PyTorch DataLoader following the DeepRC format. E.g. one of the dataloaders returned by deeprc.deeprc_binary.predefined_datasets.cmv_dataset().
- deeprc_modeldeeprc.deeprc_binary.architectures.DeepRC
DeepRC model to compute IG for. Weights of first CNN layer are accessed via deeprc_model.sequence_embedding_16bit.conv_aas.weight .
- n_stepsint
Number of IG steps (more steps -> better path integral -> finer contribution values). 50 is usually good enough.
- thresholdfloat
Threshold for plotting of kernels (=motifs). Contributions are normalized to range [0, 1] and then threshold is applied. 0.5 -> only kernels with normalized contributions above 0.5 are plotted.
- path_inputsPath
path for inputs integrated gradients plot
- path_kernelsPath
path for kernels integrated gradients plot
- plot_inputs_text(chars, colorgrad, seq_lens, file_path)[source]¶
Author – Michael Widrich Created on – 2020-07-20 Contact – michael.widrich@jku.at
- plot_kernels_text(kernels, charset, file_path)[source]¶
Author – Michael Widrich Created on – 2020-07-20 Contact – michael.widrich@jku.at
immuneML.reports.ml_reports.KernelSequenceLogo module¶
- class immuneML.reports.ml_reports.KernelSequenceLogo.KernelSequenceLogo(train_dataset: Dataset = None, test_dataset: Dataset = None, method: MLMethod = None, result_path: Path = None, name: str = None, hp_setting: HPSetting = None, label: Label = None, number_of_processes: int = 1)[source]¶
Bases:
MLReportA report that plots kernels of a CNN model as sequence logos. It works only with trained ReceptorCNN models which has kernels already normalized to represent information gain matrices. Additionally, it also plots the weights in the final fully-connected layer of the network associated with kernel outputs. For more information on how the model works, see ReceptorCNN.
The kernels are visualized using Logomaker. Original publication: Tareen A, Kinney JB. Logomaker: beautiful sequence logos in Python. Bioinformatics. 2020; 36(7):2272-2274. doi:10.1093/bioinformatics/btz921.
YAML specification:
definitions: reports: my_kernel_seq_logo: KernelSequenceLogo
- classmethod build_object(**kwargs)[source]¶
Creates the object of the subclass of the Report class from the parameters so that it can be used in the analysis. Depending on the type of the report, the parameters provided here will be provided in parsing time, while the other necessary parameters (e.g., subset of the data from which the report should be created) will be provided at runtime. For more details, see specific direct subclasses of this class, describing different types of reports.
- Parameters:
**kwargs – keyword arguments that will be provided by users in the specification (if immuneML is used as a command line tool) or in the dictionary when calling the method from the code, and which should be used to create the report object
- Returns:
the object of the appropriate report class
- check_prerequisites()[source]¶
Checks prerequisites for the generation of the report of specific class (e.g., if the class of the MLMethod instance is the one required by the report, if the data has been encoded to make a report of encoded dataset). In the instructions in immuneML, this function is used to determine whether to call generate_report() in the specific situation. Each report subclass has its own set of prerequisites. If the report cannot be run, the information on this will be logged and the report skipped in the specific situation. No error will be raised. See subclasses of the class
Instructionfor more information on how the reports are executed.- Returns:
boolean value True if the prerequisites are o.k., and False otherwise.
immuneML.reports.ml_reports.MLReport module¶
- class immuneML.reports.ml_reports.MLReport.MLReport(train_dataset: Dataset = None, test_dataset: Dataset = None, method: MLMethod = None, result_path: Path = None, name: str = None, hp_setting: HPSetting = None, label: Label = None, number_of_processes: int = 1)[source]¶
Bases:
ReportML model reports show some type of features or statistics about a single trained ML model.
In the TrainMLModel instruction, ML model reports can be specified inside the ‘selection’ or ‘assessment’ specification under the key ‘reports/models’. Example:
my_instruction: type: TrainMLModel selection: reports: models: - my_ml_report # other parameters... assessment: reports: models: - my_ml_report # other parameters... # other parameters...
- DOCS_TITLE = 'ML model reports'¶
- __init__(train_dataset: Dataset = None, test_dataset: Dataset = None, method: MLMethod = None, result_path: Path = None, name: str = None, hp_setting: HPSetting = None, label: Label = None, number_of_processes: int = 1)[source]¶
The arguments defined below are set at runtime by the instruction. Concrete classes inheriting MLReport may include additional parameters that will be set by the user in the form of input arguments.
train_dataset (Dataset): a dataset object (repertoire, receptor or sequence dataset) with encoded_data attribute set to an EncodedData object that was used for training the ML method test_dataset (Dataset): same as train_dataset, except it is not used for training and then maybe be used for testing the method method (MLMethod): a trained instance of a concrete subclass of MLMethod object result_path (Path): location where the report results will be stored hp_setting (HPSetting): a HPSetting object describing the ML method, encoding and preprocessing used label (Label): the label for which the model was trained name (str): user-defined name of the report used in the HTML overview automatically generated by the platform number_of_processes (int): how many processes should be created at once to speed up the analysis. For personal machines, 4 or 8 is usually a good choice.
immuneML.reports.ml_reports.MotifSeedRecovery module¶
- class immuneML.reports.ml_reports.MotifSeedRecovery.MotifSeedRecovery(implanted_motifs_per_label, train_dataset: Dataset = None, test_dataset: Dataset = None, method: MLMethod = None, result_path: Path = None, name: str = None, hp_setting: HPSetting = None, label=None, number_of_processes: int = 1)[source]¶
Bases:
MLReportThis report can be used to show how well implanted motifs (for example, through the Simulation instruction) can be recovered by various machine learning methods using the k-mer encoding. This report creates a boxplot, where the x axis (box grouping) represents the maximum possible overlap between an implanted motif seed and a kmer feature (measured in number of positions), and the y axis shows the coefficient size of the respective kmer feature. If the machine learning method has learned the implanted motif seeds, the coefficient size is expected to be largest for the kmer features with high overlap to the motif seeds.
Note that to use this report, the following criteria must be met:
KmerFrequencyEncoder must be used.
One of the following classifiers must be used: RandomForestClassifier, LogisticRegression, SVM, SVC
For each label, the implanted motif seeds relevant to that label must be specified
To find the overlap score between kmer features and implanted motif seeds, the two sequences are compared in a sliding window approach, and the maximum overlap is calculated.
Overlap scores between kmer features and implanted motifs are calculated differently based on the Hamming distance that was allowed during implanting.
Without hamming distance: Seed: AAA -> score = 3 Feature: xAAAx ^^^ Seed: AAA -> score = 0 Feature: xAAxx With hamming distance: Seed: AAA -> score = 3 Feature: xAAAx ^^^ Seed: AAA -> score = 2 Feature: xAAxx ^^ Furthermore, gap positions in the motif seed are ignored: Seed: A/AA -> score = 3 Feature: xAxAAx ^/^^See Recovering simulated immune signals for more details.
Example output:
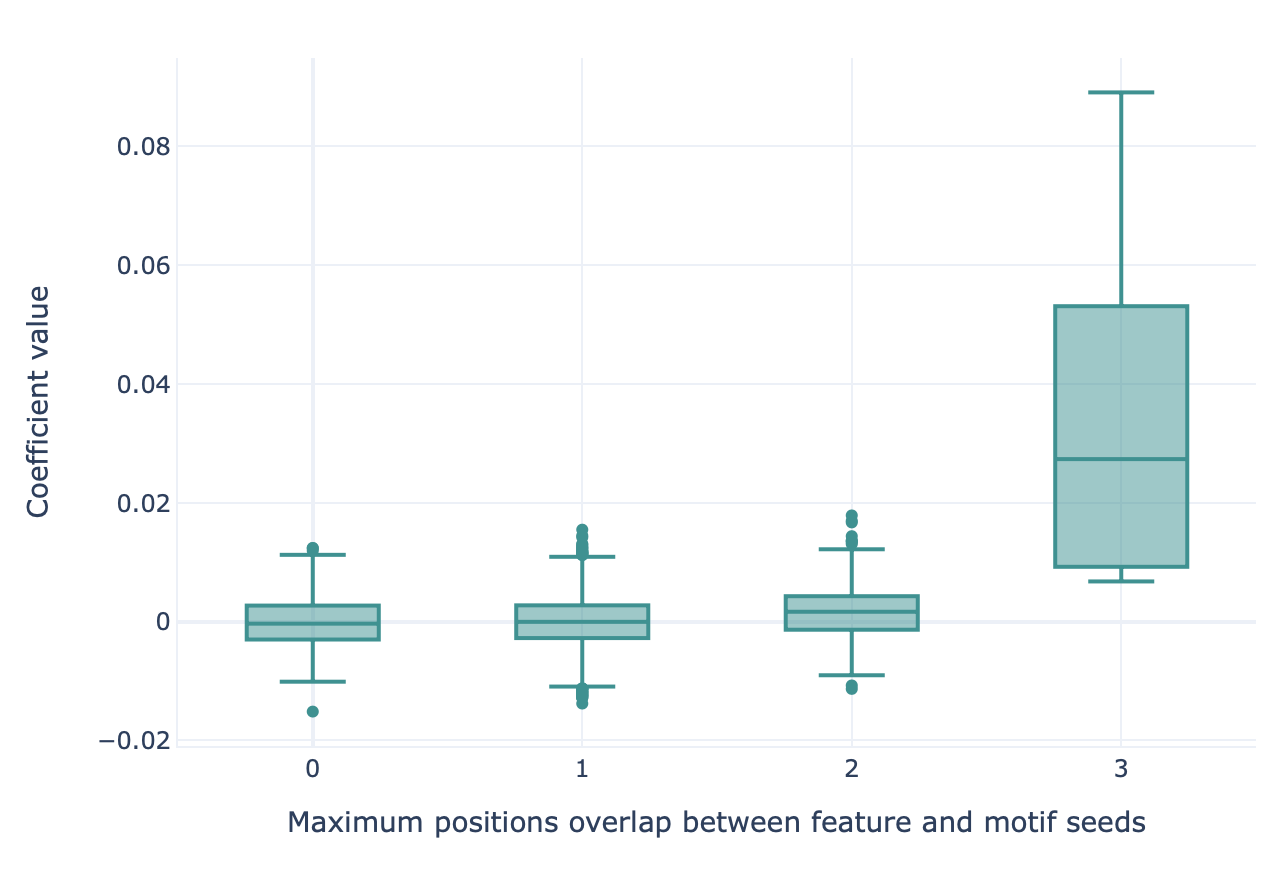
Specification arguments:
implanted_motifs_per_label (dict): a nested dictionary that specifies the motif seeds that were implanted in the given dataset. The first level of keys in this dictionary represents the different labels. In the inner dictionary there should be two keys: “seeds” and “hamming_distance”:
seeds: a list of motif seeds. The seeds may contain gaps, specified by a ‘/’ symbol.
hamming_distance: A boolean value that specifies whether hamming distance was allowed when implanting the motif seeds for a given label. Note that this applies to all seeds for this label.
gap_sizes: a list of all the possible gap sizes that were used when implanting a gapped motif seed. When no gapped seeds are used, this value has no effect.
YAML specification:
definitions: reports: my_motif_report: MotifSeedRecovery: implanted_motifs_per_label: CD: seeds: - AA/A - AAA hamming_distance: False gap_sizes: - 0 - 1 - 2 T1D: seeds: - CC/C - CCC hamming_distance: True gap_sizes: - 2
- classmethod build_object(**kwargs)[source]¶
Creates the object of the subclass of the Report class from the parameters so that it can be used in the analysis. Depending on the type of the report, the parameters provided here will be provided in parsing time, while the other necessary parameters (e.g., subset of the data from which the report should be created) will be provided at runtime. For more details, see specific direct subclasses of this class, describing different types of reports.
- Parameters:
**kwargs – keyword arguments that will be provided by users in the specification (if immuneML is used as a command line tool) or in the dictionary when calling the method from the code, and which should be used to create the report object
- Returns:
the object of the appropriate report class
- check_prerequisites()[source]¶
Checks prerequisites for the generation of the report of specific class (e.g., if the class of the MLMethod instance is the one required by the report, if the data has been encoded to make a report of encoded dataset). In the instructions in immuneML, this function is used to determine whether to call generate_report() in the specific situation. Each report subclass has its own set of prerequisites. If the report cannot be run, the information on this will be logged and the report skipped in the specific situation. No error will be raised. See subclasses of the class
Instructionfor more information on how the reports are executed.- Returns:
boolean value True if the prerequisites are o.k., and False otherwise.
immuneML.reports.ml_reports.ROCCurve module¶
- class immuneML.reports.ml_reports.ROCCurve.ROCCurve(train_dataset: Dataset = None, test_dataset: Dataset = None, method: MLMethod = None, result_path: Path = None, name: str = None, hp_setting: HPSetting = None, label: Label = None, number_of_processes: int = 1)[source]¶
Bases:
MLReportA report that plots the ROC curve for a binary classifier.
YAML specification:
definitions: reports: my_roc_report: ROCCurve
- classmethod build_object(**kwargs)[source]¶
Creates the object of the subclass of the Report class from the parameters so that it can be used in the analysis. Depending on the type of the report, the parameters provided here will be provided in parsing time, while the other necessary parameters (e.g., subset of the data from which the report should be created) will be provided at runtime. For more details, see specific direct subclasses of this class, describing different types of reports.
- Parameters:
**kwargs – keyword arguments that will be provided by users in the specification (if immuneML is used as a command line tool) or in the dictionary when calling the method from the code, and which should be used to create the report object
- Returns:
the object of the appropriate report class
- check_prerequisites()[source]¶
Checks prerequisites for the generation of the report of specific class (e.g., if the class of the MLMethod instance is the one required by the report, if the data has been encoded to make a report of encoded dataset). In the instructions in immuneML, this function is used to determine whether to call generate_report() in the specific situation. Each report subclass has its own set of prerequisites. If the report cannot be run, the information on this will be logged and the report skipped in the specific situation. No error will be raised. See subclasses of the class
Instructionfor more information on how the reports are executed.- Returns:
boolean value True if the prerequisites are o.k., and False otherwise.
immuneML.reports.ml_reports.SequenceAssociationLikelihood module¶
- class immuneML.reports.ml_reports.SequenceAssociationLikelihood.SequenceAssociationLikelihood(train_dataset: Dataset = None, test_dataset: Dataset = None, method: MLMethod = None, result_path: Path = None, name: str = None, hp_setting: HPSetting = None, label=None, number_of_processes: int = 1)[source]¶
Bases:
MLReportPlots the beta distribution used as a prior for class assignment in ProbabilisticBinaryClassifier. The distribution plotted shows the probability that a sequence is associated with a given class for a label.
YAML specification:
definitions: reports: my_sequence_assoc_report: SequenceAssociationLikelihood
- DISTRIBUTION_PERCENTAGE_TO_SHOW = 0.999¶
- STEP = 400¶
- classmethod build_object(**kwargs)[source]¶
Creates the object of the subclass of the Report class from the parameters so that it can be used in the analysis. Depending on the type of the report, the parameters provided here will be provided in parsing time, while the other necessary parameters (e.g., subset of the data from which the report should be created) will be provided at runtime. For more details, see specific direct subclasses of this class, describing different types of reports.
- Parameters:
**kwargs – keyword arguments that will be provided by users in the specification (if immuneML is used as a command line tool) or in the dictionary when calling the method from the code, and which should be used to create the report object
- Returns:
the object of the appropriate report class
- check_prerequisites()[source]¶
Checks prerequisites for the generation of the report of specific class (e.g., if the class of the MLMethod instance is the one required by the report, if the data has been encoded to make a report of encoded dataset). In the instructions in immuneML, this function is used to determine whether to call generate_report() in the specific situation. Each report subclass has its own set of prerequisites. If the report cannot be run, the information on this will be logged and the report skipped in the specific situation. No error will be raised. See subclasses of the class
Instructionfor more information on how the reports are executed.- Returns:
boolean value True if the prerequisites are o.k., and False otherwise.
immuneML.reports.ml_reports.TCRdistMotifDiscovery module¶
- class immuneML.reports.ml_reports.TCRdistMotifDiscovery.TCRdistMotifDiscovery(train_dataset: ReceptorDataset = None, test_dataset: ReceptorDataset = None, method: MLMethod = None, result_path: Path = None, name: str = None, cores: int = None, context: dict = None, positive_class_name=None, min_cluster_size: int = None, use_reference_sequences: bool = None, hp_setting: HPSetting = None, label=None, number_of_processes: int = 1)[source]¶
Bases:
MLReportThe report for discovering motifs in paired immune receptor data of given specificity based on TCRdist3. The receptors are hierarchically clustered based on the tcrdist distance and then motifs are discovered for each cluster. The report outputs logo plots for the motifs along with the raw data used for plotting in csv format.
For the implementation, TCRdist3 library was used (source code available here). More details on the functionality used for this report are available here.
Original publications:
Dash P, Fiore-Gartland AJ, Hertz T, et al. Quantifiable predictive features define epitope-specific T cell receptor repertoires. Nature. 2017; 547(7661):89-93. doi:10.1038/nature22383
Mayer-Blackwell K, Schattgen S, Cohen-Lavi L, et al. TCR meta-clonotypes for biomarker discovery with tcrdist3: quantification of public, HLA-restricted TCR biomarkers of SARS-CoV-2 infection. bioRxiv. Published online December 26, 2020:2020.12.24.424260. doi:10.1101/2020.12.24.424260
Example output:


Specification arguments:
positive_class_name (str): the class value (e.g., epitope) used to select only the receptors that are specific to the given epitope so that only those sequences are used to infer motifs; the reference receptors as required by TCRdist will be the ones from the dataset that have different or no epitope specified in their metadata; if the labels are available only on the epitope level (e.g., label is “AVFDRKSDAK” and classes are True and False), then here it should be specified that only the receptors with value “True” for label “AVFDRKSDAK” should be used; there is no default value for this argument
cores (int): number of processes to use for the computation of the distance and motifs
min_cluster_size (int): the minimum size of the cluster to discover the motifs for
use_reference_sequences (bool): when showing motifs, this parameter defines if reference sequences should be provided as well as a background
YAML specification:
definitions: reports: my_tcr_dist_report: # user-defined name TCRdistMotifDiscovery: positive_class_name: True # class name, could also be epitope name, depending on how it's defined in the dataset cores: 4 min_cluster_size: 30 use_reference_sequences: False
- classmethod build_object(**kwargs)[source]¶
Creates the object of the subclass of the Report class from the parameters so that it can be used in the analysis. Depending on the type of the report, the parameters provided here will be provided in parsing time, while the other necessary parameters (e.g., subset of the data from which the report should be created) will be provided at runtime. For more details, see specific direct subclasses of this class, describing different types of reports.
- Parameters:
**kwargs – keyword arguments that will be provided by users in the specification (if immuneML is used as a command line tool) or in the dictionary when calling the method from the code, and which should be used to create the report object
- Returns:
the object of the appropriate report class
- check_prerequisites()[source]¶
Checks prerequisites for the generation of the report of specific class (e.g., if the class of the MLMethod instance is the one required by the report, if the data has been encoded to make a report of encoded dataset). In the instructions in immuneML, this function is used to determine whether to call generate_report() in the specific situation. Each report subclass has its own set of prerequisites. If the report cannot be run, the information on this will be logged and the report skipped in the specific situation. No error will be raised. See subclasses of the class
Instructionfor more information on how the reports are executed.- Returns:
boolean value True if the prerequisites are o.k., and False otherwise.
- set_context(context: dict)[source]¶
Context is a dictionary with information that is accessible from the level of instruction and can be used to precompute certain values that can be later reused to speed up the generation of the subsequent reports of the same time. For instance, if one should compute the distance between all repertoires based on the sequence content, it is possible to store the full dataset in the context, compute the distances on the full dataset and then only extract the distances need for the current dataset in the later calls (e.g., when training dataset is passed as input). Only some reports will need this functionality.
Warning: It is very important to be careful when using the context to avoid leaking the information between training and test datasets.
- Parameters:
context (dict) – a dictionary where the values are variables that are typically only available on the top-level of the instruction, and which are used to precompute results in order to speed up subsequent generation of the same report on subsets of those values.
- Returns:
self - so that it can be chained with the other function calls
immuneML.reports.ml_reports.TrainingPerformance module¶
- class immuneML.reports.ml_reports.TrainingPerformance.TrainingPerformance(metrics: set, train_dataset: ~immuneML.data_model.datasets.Dataset.Dataset = None, test_dataset: ~immuneML.data_model.datasets.Dataset.Dataset = None, method: ~immuneML.ml_methods.classifiers.MLMethod.MLMethod = None, result_path: ~pathlib.Path = None, name: str = None, hp_setting: <module 'immuneML.hyperparameter_optimization.HPSetting' from '/Users/milenpa/PycharmProjects/BMIimmuneML/immuneML/hyperparameter_optimization/HPSetting.py'> = None, label=None, number_of_processes: int = 1)[source]¶
Bases:
MLReportA report that plots the evaluation metrics for the performance given machine learning model and training dataset. The available metrics are accuracy, balanced_accuracy, confusion_matrix, f1_micro, f1_macro, f1_weighted, precision, recall, auc and log_loss (see
immuneML.environment.Metric.Metric).Specification arguments:
metrics (list): A list of metrics used to evaluate training performance. See
immuneML.environment.Metric.Metricfor available options.
YAML specification:
definitions: reports: my_performance_report: TrainingPerformance: metrics: - accuracy - balanced_accuracy - confusion_matrix - f1_micro - f1_macro - f1_weighted - precision - recall - auc - log_loss
- classmethod build_object(**kwargs)[source]¶
Creates the object of the subclass of the Report class from the parameters so that it can be used in the analysis. Depending on the type of the report, the parameters provided here will be provided in parsing time, while the other necessary parameters (e.g., subset of the data from which the report should be created) will be provided at runtime. For more details, see specific direct subclasses of this class, describing different types of reports.
- Parameters:
**kwargs – keyword arguments that will be provided by users in the specification (if immuneML is used as a command line tool) or in the dictionary when calling the method from the code, and which should be used to create the report object
- Returns:
the object of the appropriate report class
- check_prerequisites() bool[source]¶
Checks prerequisites for the generation of the report of specific class (e.g., if the class of the MLMethod instance is the one required by the report, if the data has been encoded to make a report of encoded dataset). In the instructions in immuneML, this function is used to determine whether to call generate_report() in the specific situation. Each report subclass has its own set of prerequisites. If the report cannot be run, the information on this will be logged and the report skipped in the specific situation. No error will be raised. See subclasses of the class
Instructionfor more information on how the reports are executed.- Returns:
boolean value True if the prerequisites are o.k., and False otherwise.